 Programmierhandbuch
Programmierhandbuch

1. Einleitung
2. Expertensysteme
3. Komponenten eines Expertensystems
| WENN A gilt, | DANN muß auch B gelten; |
| WENN aber B gilt, | DANN muß auch C wahr sein; |
| usw. |
Da die Fachexperten selbst ihr Wissen häufig in Form solcher WENN-DANN-Aussagen verbalisieren, wird der Vorteil dieses Funktionsprinzips leicht sichtbar.
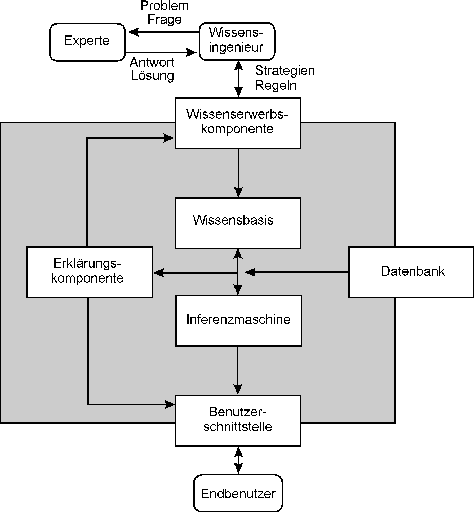
Bild P1: Komponenten eines Expertensystems
| Werkzeug | Anbieter | Preis Einzellizenz für UNIX |
|---|---|---|
| KEE | Intellicorp | 70 000,- DM |
| Nexpert Object | Neuron Data | 30 000,- DM |
| babylon-3 | VW-Gedas | 18 000,- DM |
Tabelle P1: Bekannte große hybride dialogorientierte Expertensystemschalen
4. Arten von Wissen
5. Wissensrepräsentation in hybriden Expertensystemschalen
5.1 Programmiersprachen in der künstlichen Intelligenz
5.2 Semantische Netze

Bild P2: Aufbau eines semantischen Netzes
5.3 Objektorientierung
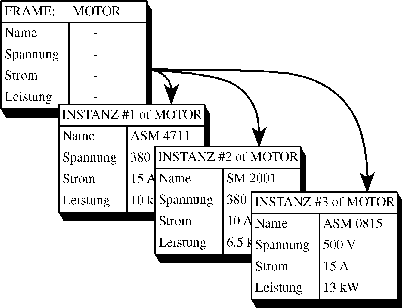
Bild P3: Frames und Instanzen
5.4 Produktionsregeln
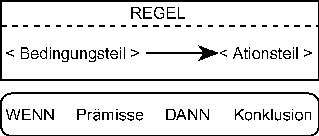
|
WENN der Bedingungsteil (Prämisse) erfüllt ist,
DANN wird der Aktionsteil (Konklusion) abgearbeitet. |
Bild P4: Aufbau einer Regel
Durch das Anwenden von Regeln auf bereits bekannte Fakten können neue Fakten gewonnen werden.
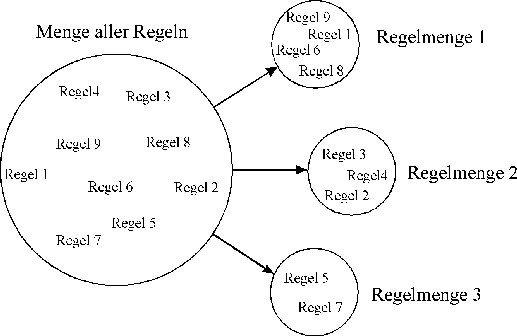
Bild P5: Aufteilung der Regeln einer Wissensbasis in Regelmengen

Bild P6: Strategien für die Verkettung von Regeln
5.5 Prädikatenlogik
5.6 Constraints

Bild P7: Ein einfacher Zwang (Constraint) |

Bild P8: Ein Constraint-Netz |